Databases: how they work, and a brief history
My twitter-friend Simon had a simple question that contained much complexity: how do databases work?
Ok, so databases really confuse me, like how do databases even work?
— Simon Legg (@simonleggsays) November 18, 2019
I don't have a job at the moment, and I really love databases and also teaching things to web developers, so this was a perfect storm for me:
To what level of detail would you like an answer? I love databases.
— Laurie Voss (@seldo) November 18, 2019
The result was an absurdly long thread of 70+ tweets, in which I expounded on the workings and history of databases as used by modern web developers, and Simon chimed in on each tweet with further questions and requests for clarification. The result of this collaboration was a super fun tiny explanation of databases which many people said they liked, so here it is, lightly edited for clarity.
What is a database?
Let's start at the very most basic thing, the words we're using: a "database" literally just means "a structured collection of data". Almost anything meets this definition – an object in memory, an XML file, a list in HTML. It's super broad, so we call some radically different things "databases".
The thing people use all the time is, formally, a Database Management System, abbreviated to DBMS. This is a piece of software that handles access to the pile of data. Technically one DBMS can manage multiple databases (MySQL and postgres both do this) but often a DBMS will have just one database in it.
Because it's so frequent that the DBMS has one DB in it we often call a DBMS a "database". So part of the confusion around databases for people new to them is because we call so many things the same word! But it doesn't really matter, you can call an DBMS a "database" and everyone will know what you mean. MySQL, Redis, Postgres, RedShift, Oracle etc. are all DBMS.
So now we have a mental model of a "database", really a DBMS: it is a piece of software that manages access to a pile of structured data for you. DBMSes are often written in C or C++, but it can be any programming language; there are databases written in Erlang and JavaScript. One of the key differences between DBMSes is how they structure the data.
Relational databases
Relational databases, also called RDBMS, model data as a table, like you'd see in a spreadsheet. On disk this can be as simple as comma-separated values: one row per line, commas between columns, e.g. a classic example is a table of fruits:
apple,10,5.00
orange,5,6.50
The DBMS knows the first column is the name, the second is the number of fruits, the third is the price. Sometimes it will store that information in a different database! Sometimes the metadata about what the columns are will be in the database file itself. Because it knows about the columns, it can handle niceties for you: for example, the first column is a string, the second is an integer, the third is dollar values. It can use that to make sure it returns those columns to you correctly formatted, and it can also store numbers more efficiently than just strings of digits.
In reality a modern database is doing a whole bunch of far more clever optimizations than just comma separated values but it's a mental model of what's going on that works fine. The data all lives on disk, often as one big file, and the DBMS caches parts of it in memory for speed. Sometimes it has different files for the data and the metadata, or for indexes that make it easier to find things quickly, but we can safely ignore those details.
RDBMS are older, so they date from a time when memory was really expensive, so they usually optimize for keeping most things on disk and only put some stuff in memory. But they don't have to: some RDBMS keep everything in memory and never write to disk. That makes them much faster!
Is it still a database if all the structured data stays in memory? Sure. It's a pile of structured data. Nothing in that definition says a disk needs to be involved.
So what does the "relational" part of RDBMS mean? RDBMS have multiple tables of data, and they can relate different tables to each other. For instance, imagine a new table called "Farmers":
| ID | Name |
| 1 | bob |
| 2 | susan |
and we modify the Fruits table:
| Farmer ID | Fruit | Quantity | Price |
| 1 | apple | 10 | 5.00 |
| 1 | orange | 5 | 6.50 |
| 2 | apple | 20 | 6.00 |
| 2 | orange | 1 | 4.75 |
The Farmers table gives each farmer a name and an ID. The Fruits table now has a column that gives the Farmer ID, so you can see which farmer has which fruit at which price.
Why's that helpful? Two reasons: space and time. Space because it reduces data duplication. Remember, these were invented when disks were expensive and slow! Storing the data this way lets you only list "susan" once no matter how many fruits she has. If she had a hundred kinds of fruit you'd be saving quite a lot of storage by not repeating her name over and over. The time reason comes in if you want to change Susan's name. If you repeated her name hundreds of times you would have to do a write to disk for each one (and writes were very slow at the time this was all designed). That would take a long time, plus there's a chance you could miss one somewhere and suddenly Susan would have two names and things would be confusing.
Relational databases make it easy to do certain kinds of queries. For instance, it's very efficient to find out how many fruits there are in total: you just add up all the numbers in the Quantity column in Fruits, and you never need to look at Farmers at all. It's efficient and because the DBMS knows where the data is you can say "give me the sum of the quantity colum" pretty simply in SQL, something like SELECT SUM(Quantity) FROM Fruits. The DBMS will do all the work.
NoSQL databases
So now let's look at the NoSQL databases. These were a much more recent invention, and the economics of computer hardware had changed: memory was a lot cheaper, disk space was absurdly cheap, processors were a lot faster, and programmers were very expensive. The designers of newer databases could make different trade-offs than the designers of RDBMS.
The first difference of NoSQL databases is that they mostly don't store things on disk, or do so only once in a while as a backup. This can be dangerous – if you lose power you can lose all your data – but often a backup from a few minutes or seconds ago is fine and the speed of memory is worth it. A database like Redis writes everything to disk every 200ms or so, which is hardly any time at all, while doing all the real work in memory.
A lot of the perceived performance advantages of "noSQL" databases is just because they keep everything in memory and memory is very fast and disks, even modern solid-state drives, are agonizingly slow by comparison. It's nothing to do with whether the database is relational or not-relational, and nothing at all to do with SQL.
But the other thing NoSQL database designers did was they abandoned the "relational" part of databases. Instead of the model of tables, they tended to model data as objects with keys. A good mental model of this is just JSON:
[
{"name":"bob"}
{"name":"susan","age":55}
]
Again, just as a modern RDBMS is not really writing CSV files to disk but is doing wildly optimized stuff, a NoSQL database is not storing everything as a single giant JSON array in memory or disk, but you can mentally model it that way and you won't go far wrong. If I want the record for Bob I ask for ID 0, Susan is ID 1, etc..
One advantage here is that I don't need to plan in advance what I put in each record, I can just throw anything in there. It can be just a name, or a name and an age, or a gigantic object. With a relational DB you have to plan out columns in advance, and changing them later can be tricky and time-consuming.
Another advantage is that if I want to know everything about a farmer, it's all going to be there in one record: their name, their fruits, the prices, everything. In a relational DB that would be more complicated, because you'd have to query the farmers and fruits tables at the same time, a process called "joining" the tables. The SQL "JOIN" keyword is one way to do this.
One disadvantage of storing records as objects like this, formally called an "object store", is that if I want to know how many fruits there are in total, that's easy in an RDBMS but harder here. To sum the quantity of fruits, I have to retrieve each record, find the key for fruits, find all the fruits, find the key for quantity, and add these to a variable. The DBMS for the object store may have an API to do this for me if I've been consistent and made all the objects I stored look the same. But I don't have to do that, so there's a chance the quantities are stored in different places in different objects, making it quite annoying to get right. You often have to write code to do it.
But sometimes that's okay! Sometimes your app doesn't need to relate things across multiple records, it just wants all the data about a single key as fast as possible. Relational databases are best for the former, object stores the best for the latter, but both types can answer both types of questions.
Some of the optimizations I mentioned both types of DBMS use are to allow them to answer the kinds of questions they're otherwise bad at. RDBMS have "object" columns these days that let you store object-type things without adding and removing columns. Object stores frequently have "indexes" that you can set up to be able to find all the keys in a particular place so you can sum up things like Quantity or search for a specific Fruit name fast.
So what's the difference between an "object store" and a "noSQL" database? The first is a formal name for anything that stores structured data as objects (not tables). The second is... well, basically a marketing term. Let's digress into some tech history!
The self-defeating triumph of MySQL
Back in 1995, when the web boomed out of nowhere and suddenly everybody needed a database, databases were mostly commercial software, and expensive. To the rescue came MySQL, invented 1995, and Postgres, invented 1996. They were free! This was a radical idea and everybody adopted them, partly because nobody had any money back then – the whole idea of making money from websites was new and un-tested, there was no such thing as a multi-million dollar seed round. It was free or nothing.
The primary difference between PostgreSQL and MySQL was that Postgres was very good and had lots of features but was very hard to install on Windows (then, as now, the overwhelmingly most common development platform for web devs). MySQL did almost nothing but came with a super-easy installer for Windows. The result was MySQL completely ate Postgres' lunch for years in terms of market share.
Lots of database folks will dispute my assertion that the Windows installer is why MySQL won, or that MySQL won at all. But MySQL absolutely won, and it was because of the installer. MySQL became so popular it became synonymous with "database". You started any new web app by installing MySQL. Web hosting plans came with a MySQL database for free by default, and often no other databases were even available on cheaper hosts, which further accelerated MySQL's rise: defaults are powerful.
The result was people using mySQL for every fucking thing, even for things it was really bad at. For instance, because web devs move fast and change things they had to add new columns to tables all the time, and as I mentioned RDBMS are bad at that. People used MySQL to store uploaded image files, gigantic blobs of binary data that have no place in a DBMS of any kind.
People also ran into a lot of problems with RDBMS and MySQL in particular being optimized for saving memory and storing everything on disk. It made huge databases really slow, and meanwhile memory had got a lot cheaper. Putting tons of data in memory had become practical.
The rise of in-memory databases
The first software to really make use of how cheap memory had become was Memcache, released in 2003. You could run your ordinary RDBMS queries and just throw the results of frequent queries into Memcache, which stored them in memory so they were way, WAY faster to retrieve the second time. It was a revolution in performance, and it was an easy optimization to throw into your existing, RDBMS-based application.
By 2009 somebody realized that if you're just throwing everything in a cache anyway, why even bother having an RDBMS in the first place? Enter MongoDB and Redis, both released in 2009. To contrast themselves with the dominant "MySQL" they called themselves "NoSQL".
What's the difference between an in-memory cache like Memcache and an in-memory database like Redis or MongoDB? The answer is: basically nothing. Redis and Memcache are fundamentally almost identical, Redis just has much better mechanisms for retrieving and accessing the data in memory. A cache is a kind of DB, Memcache is a DBMS, it's just not as easy to do complex things with it as Redis.
Part of the reason Mongo and Redis called themselves NoSQL is because, well, they didn't support SQL. Relational databases let you use SQL to ask questions about relations across tables. Object stores just look up objects by their key most of the time, so the expressiveness of SQL is overkill. You can just make an API call like get(1) to get the record you want.
But this is where marketing became a problem. The NoSQL stores (being in memory) were a lot faster than the relational DBMS (which still mostly used disk). So people got the idea that SQL was the problem, that SQL was why RDBMS were slow. The name "NoSQL" didn't help! It sounded like getting rid of SQL was the point, rather than a side effect. But what most people liked about the NoSQL databases was the performance, and that was just because memory is faster than disk!
Of course, some people genuinely do hate SQL, and not having to use SQL was attractive to them. But if you've built applications of reasonable complexity on both an RDBMS and an object store you'll know that complicated queries are complicated whether you're using SQL or not. I have a lot of love for SQL.
If putting everything in memory makes your database faster, why can't you build an RDBMS that stores everything in memory? You can, and they exist! VoltDB is one example. They're nice! Also, MySQL and Postgres have kind of caught up to the idea that machines have lots more RAM now, so you can configure them to keep things mostly in memory too, so their default performance is a lot better and their performance after being tuned by an expert can be phenomenal.
So anything that's not a relational database is technically a "NoSQL" database. Most NoSQL databases are object stores but that's really just kind of a historical accident.
How does my app talk to a database?
Now we understand how a database works: it's software, running on a machine, managing data for you. How does your app talk to the database over a network and get answers to queries? Are all databases just a single machine?
The answer is: every DBMS, whether relational or object store, is a piece of software that runs on machine(s) that hold the data. There's massive variation: some run on 1 machine, some on clusters of 5-10, some run across thousands of separate machines all at once.
The DBMS software does the management of the data, in memory or on disk, and it presents an API that can be accessed locally, and also more importantly over the network. Sometimes this is a web API like you're used to, literally making GET and POST calls over HTTP to the database. For other databases, especially the older ones, it's a custom protocol.
Either way, you run a piece of software in your app, usually called a Client. That client knows the protocol for talking to the database, whether it's HTTP or WhateverDBProtocol. You tell it where the database server is on the network, it sends queries over and gets responses. Sometimes the queries are literally strings of text, like "SELECT * FROM Fruits", sometimes they are JSON payloads describing records, and any number of other variations.
As a starting point, you can think of the client running on your machine talking over the network to a database running on another machine. Sometimes your app is on dozens of machines, and the database is a single IP address with thousands of machines pretending to be one machine. But it works pretty much the same either way.
The way you tell your client "where" the DB is is your connection credentials, often expressed as a string like "http://username:password@mydb.com:1234" or "mongodb://...". But this is just a convenient shorthand. All your client really needs to talk to a database is the DNS name (like mydb.com) or an IP address (like 205.195.134.39), plus a port (1234). This tells the network which machine to send the query to, and what "door" to knock on when it gets there.
A little about ports: machines listen on specific ports for things, so if you send something to port 80, the machine knows the query is for your web server, but if you send it to port 1234, it knows the query is for your database. Who picks 1234 (In the case of Postgres, it's literally 5432)? There's no rhyme or reason to it. The developers pick a number that's easy to remember between 1 and 65,535 (the highest port number available) and hope that no other popular piece of software is already using it.
Usually you'll also have a username and password to connect to the database, because otherwise anybody who found your machine could connect to your database and get all the data in it. Forgetting that this is true is a really common source of security breaches!
There are bad people on the internet who literally just try every single IP in the world and send data to the default port for common databases and try to connect without a username or password to see if they can. If it works, they take all the data and then ransom it off. Yikes! Always make sure your database has a password.
Of course, sometimes you don't talk to your database over a network. Sometimes your app and your database live on the same machine. This is common in desktop software but very rare in web apps. If you've ever heard of a "database driver", the "driver" is the equivalent of the "client", but for talking to a local database instead of over a network.
Replication and scaling
Remember I said some databases run on just 1 machine, and some run on thousands of machines? That's known as replication. If you have more than one copy of a piece of data, you have a "replica" of that data, hence the name.
Back in the old days hardware was expensive so it was unusual to have replicas of your data running at the same time. It was expensive. Instead you'd back up your data to tape or something, and if the database went down because the hardware wore out or something, then you'd buy new hardware and (hopefully) reinstall your DBMS and restore the data in a few hours.
Web apps radically changed people's demands of databases. Before web apps, most databases weren't being continuously queried by the public, just a few experts inside normal working hours, and they would wait patiently if the database broke. With a web app you can't have minutes of downtime, far less hours, so replication went from being a rare feature of expensive databases to pretty much table stakes for every database. The initial form of replication was a "hot spare".
If you ran a hot spare, you'd have your main DBMS machine, which handled all queries, and a replica DBMS machine that would copy every single change that happened on the primary to itself. Primary was called m****r and the replica s***e because the latter did whatever the former told it to do, and at the time nobody considered how horrifying that analogy was. These days we call those things "primary/secondary" or "primary/replica" or for more complicated arrangements things like "root/branch/leaf".
Sometimes, people would think having a hot spare meant they didn't need a backup. This is a huge mistake! Remember, the replica copies every change in the main database. So if you accidentally run a command that deletes all the data in your primary database, it will automatically delete all the data in the replica too. Replicas are not backups, as the bookmarking site Magnolia famously learned.
People soon realized having a whole replica machine sitting around doing nothing was a waste, so to be more efficient they changed where traffic went: all the writes would go to the primary, which would copy everything to the replicas, and all the reads would go to the replicas. This was great for scale!
Instead of having 1 machine worth of performance (and you could swap to the hot spare if it failed, and still have 1 machine of performance with no downtime) suddenly you had X machines of performance, where X could be dozens or even hundreds. Very helpful!
But primary/secondary replication of this kind has two drawbacks. First, if a write has arrived at the primary database but not yet replicated to all the secondary machines (which can take half a second if the machines are far apart or overloaded) then somebody reading from the replica can get an answer that's out of date. This is known as a "consistency" failure, and we'll talk about it more later.
The second flaw with primary/second replication is if the primary fails, suddenly you can no longer write to your database. To restore the ability to do writes, you have to take one of the replicas and "promote" it to primary, and change all the other replicas to point at this new primary box. It's time-consuming and notoriously error-prone.
So newer databases invented different ways of arranging the machines, formally called "network topology". If you think of the way machines connect to each other as a diagram, the topology is the shape of that diagram. Primary/secondary looks like a star. Root/branch/leaf looks like a tree. But you can have a ring structure, or a mesh structure, or lots of others. A mesh structure is a lot of fun and very popular, so let's talk about more about them.
Mesh replication databases
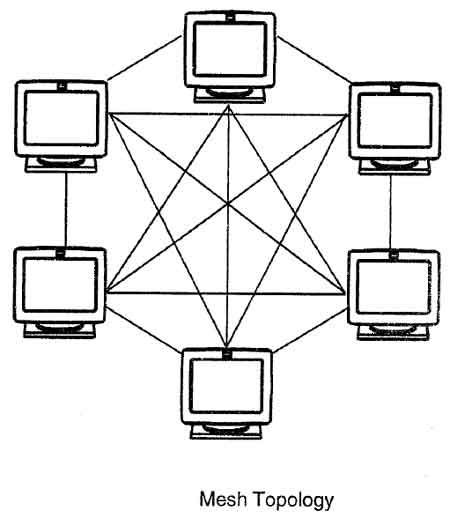
In a mesh structure, every machine is talking to every other machine and they all have some portion of the data. You can send a write to any machine and it will either store it, or figure out what machine should store it and send it to that machine. Likewise, you can query any machine in the mesh, and it will give you the answer if it has the data, or forward your request to a machine that does. There's no "primary" machine to fail. Neat!
Because each machine can get away with storing only some of the data and not all of it, a mesh database can store much, much more data than a single machine could store. If 1 machine could store X data, then N machines could theoretically store N*X data. You can almost scale infinitely that way! It's very cool.
Of course, if each record only existed on one machine, then if that machine failed you'd lose those records. So usually in a mesh network more than one machine will have a copy of any individual record. That means you can lose machines without losing data or experiencing downtime; there are other copies lying around. In some mesh databases can also add a new machine to the mesh and the others will notice it and "rebalance" data, increasing the capacity of the database without any downtime. Super cool.
So a mesh topology is a lot more complicated but more resilient, and you can scale it without having to take the database down (usually). This is very nice, but can go horribly wrong if, for instance, there's a network error and suddenly half the machines can't see the other half of the machines in the mesh. This is called a "network partition" and it's a super common failure in large networks. Usually a partition will last only a couple of seconds but that's more than enough to fuck up a database. We'll talk about network partitions shortly.
One important question about a mesh DB is: how do you connect to it? Your client needs to know an IP address to connect to a database. Does it need to know the IP addresses of every machine in the mesh? And what happens when you add and remove machines from the mesh? Sounds messy.
Different Mesh DBs do it differently, but usually you get a load balancer, another machine that accepts all the incoming connections and works out which machine in the mesh should get the question and hands it off. Of course, this means the load balancer can fail, hosing your DB. So usually you'll do some kind of DNS/IP trickery where there are a handful of load balancers all responding on the same domain name or IP address.
The end result is your client magically just needs to know only one name or IP, and that IP always responds because the load balancer always sends you to a working machine.
CAP theory
This brings us neatly to a computer science term often used to talk about databases which is Consistency, Availability, and Partition tolerance, aka CAP or "CAP theory". The basic rule of CAP theory is: you can't have all 3 of Consistency, Availability and Partition Tolerance at the same time. Not because we're not smart enough to build a database that good, but because doing so violates physics.
Consistency means, formally: every query gets the correct, most up-to-date answer (or an error response saying you can't have it).
Availability means: every query gets an answer (but it's not guaranteed to be the correct one).
Partition Tolerance means: if the network craps out, the database will continue to work.
You can already see how these conflict! If you're 100% Available it means by definition you'll never give an error response, so sometimes the data will be out of date, i.e. not Consistent. If your database is Partition Tolerant, on the other hand, it keeps working even if machine A can't talk to machine B, and machine A might have a more recent write than B, so machine B will give stale (i.e. not Consistent) responses to keep working.
So let's think about how CAP theorem applies across the topologies we already talked about.
A single DB on a single machine is definitely Consistent (there's only one copy of the data) and Partition Tolerant (there's no network inside of it to crap out) but not Available because the machine itself can fail, e.g. the hardware could literally break or power could go out.
A primary DB with several replicas is Available (if one replica fails you can ask another) and Partition Tolerant (the replicas will respond even if they're not receiving writes from the primary) but not Consistent (because as mentioned earlier, the replicas might not have every primary write yet).
A mesh DB is extremely Available (all the nodes always answer) and Partition Tolerant (just try to knock it over! It's delightfully robust!) but can be extremely inconsistent because two different machines on the mesh could get a write to the same record at the same time and fight about which one is "correct".
This is the big disadvantage to mesh DBs, which otherwise are wonderful. Sometimes it's impossible to know which of two simultaneous writes is the "winner". There's no single authority, and Very Very Complicated Algorithms are deployed trying to prevent fights breaking out between machines in the mesh about this, with highly variable levels of success and gigantic levels of pain when they inevitably fail. You can't get all three of CAP and Consistency is what mesh networks lose.
In all databases, CAP isn't a set of switches where you are or aren't Consistent, Available, or Partition Tolerant. It's more like a set of sliders. Sliding up the Partition Tolerance generally slides down Consistency, sliding down Availability will give you more Consistency, etc etc.. Every DBMS picks some combination of CAP and picking the right database is often a matter of choosing what CAP combination is appropriate for your application.
Other topologies
Some other terms you frequently hear in the world of databases are "partitions" (which are different from the network partitions of CAP theorem) and "shards". These are both additional topologies available to somebody designing a database. Let's talk about shards first.
Imagine a primary with multiple replicas, but instead of each replica having all the data, each replica has a slice (or shard) of the data. You can slice the data lots of ways. If the database was people, you could have 26 shards, one with all names starting with A, one with all the names starting with B, etc..
Sharding can be helpful if the data is too big to all fit on one disk at a time. This is less of a problem than it used to be because virtual machines these days can effectively have infinity-sized hard drives.
The disadvantage of sharding is it's less Available: if you lose a shard, you lose everybody who starts with that letter! (Of course, your shards can also have replicas...) Plus your software needs to know where all the shards are and which one to ask a question. It's fiddly. Many of the problems of sharded databases are solved by using mesh topologies instead.
Partitions are another way of splitting up a database, but instead of splitting it across many machines, it splits the database across many files in a single machine. This is an old pattern that was useful when you had really powerful hardware and really slow disks, because you could install multiple disks into a single machine and put different partitions on each one, speeding up your achingly slow, disk-based database. These days there's not a lot of reason to use partitions of this kind.
Fin
That concludes this impromptu Databases 101 seminar! I hope you enjoyed learning a little bit more about this fantastically fun and critically important genre of software.
