What I've learned about data recently
I've been a web developer for 25 years now. In the last 10 years, at two different companies, my focus has increasingly shifted to working with what is somewhat eye-rollingly referred to as "big data" but I will just be calling "data". In the last 18 months, since I joined Netlify, I feel like I have really leveled up from "just do whatever works" to feeling like there's a Right Way to do it.
I like to share when I learn things, so that's what this blog post is about. But admitting that I've learned things involves admitting not knowing things. Admitting I spent 8 years doing data things without using what in retrospect feels like basic tooling involves a certain amount of vulnerability. But whatever, I've done dumber stuff and more publicly. If this post teaches you nothing, well done. If you learn something, I hope this helps you climb the learning curve faster than I did.
Learning 1: you want engineers, not scientists
I learned this one before I was even hired at Netlify. While deciding about my next career step, I interviewed at a bunch of companies who were doing data-related things. Some were very sophisticated in how they handled data, but they were a minority. There was one pattern in particular I saw repeated over and over: a fast growing company would say "wow, we have all this data, we should do something with it". Then they would go out and hire a Data Scientist, ideally with a PhD, as their very first data hire. This is how that is imagined to work:
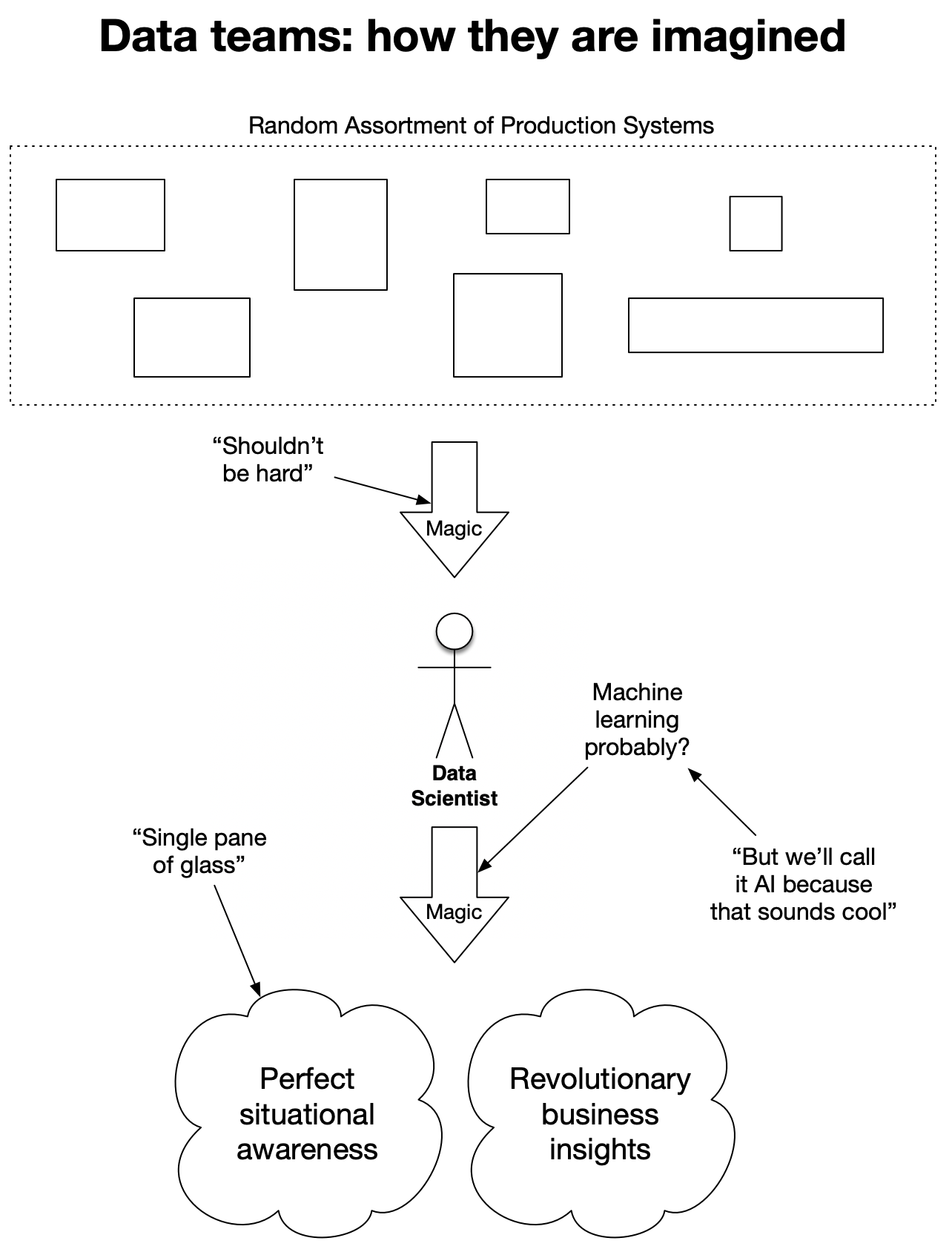
This is a mistake. Firstly, the term "Data Scientist" is over-used to the point of being meaningless. To me, a data scientist is an academic with very advanced degrees. They advance the state of the art in modeling, they solve novel problems in machine learning. They write white papers in journals. This is not what you need. Unless "we solve a new problem in machine learning" is what your company was founded to do, this is not what you need done. What you need is a data engineer.
The problem you actually have is: "we are generating a ton of data, but we have no idea what's going on". On the face of it, it sounds like somebody called a "data scientist" is the right person to solve that! But to actually solve your problem, what you need to do is:
- Work with the engineers on your team to instrument your code so it's generating usable data in the first place.
- Extract all your data from the random places it's accumulating, in a zillion incompatible formats
- Load it all into some kind of central store, so that you can compare and correlate data coming from different sources
- Transform the data from its raw state into answers to questions, either as a one-time analysis or as an ongoing report or dashboard
- Figure out what the right questions are for the business to be asking, and what strategic changes are dictated by the answers you get.
(Side note: there is a small revolution ongoing in the data space about the shift from "Extract-Transform-Load" to "Extract-Load-Transform"; the difference is that previously your central store was probably not big enough to hold all of your raw data, so you'd need to aggregate it down first, i.e. transform it, before you could put it into your central store, now your central store is so huge you can just throw everything in there as-is, and transform it later, i.e. load it first. It is quite a lot of fuss for such a simple change.)
Where the person I call a "data scientist" comes in is step 4, and not most of the time. Maybe 5% of the time the kind of advanced analysis a data scientist can bring to bear is going to provide utility over what a simpler, more straightforward analysis could provide. The problem is, if your first hire is an academic with a PhD, they will never even get to step 4. They will get stuck in steps 1-3, getting increasingly frustrated, because those things are not their primary skill set.
What you need instead is engineers and analysts to take care of each step. In practice, you might not have a separate person for each of these roles, and even if you have a larger team, people will skip back and forth between the somewhat arbitrary divisions I've created here. In the real world, your analysts have to do engineering sometimes, and your engineers will be more effective if they can predict how the analysis is going to go. It's going to look more like this:
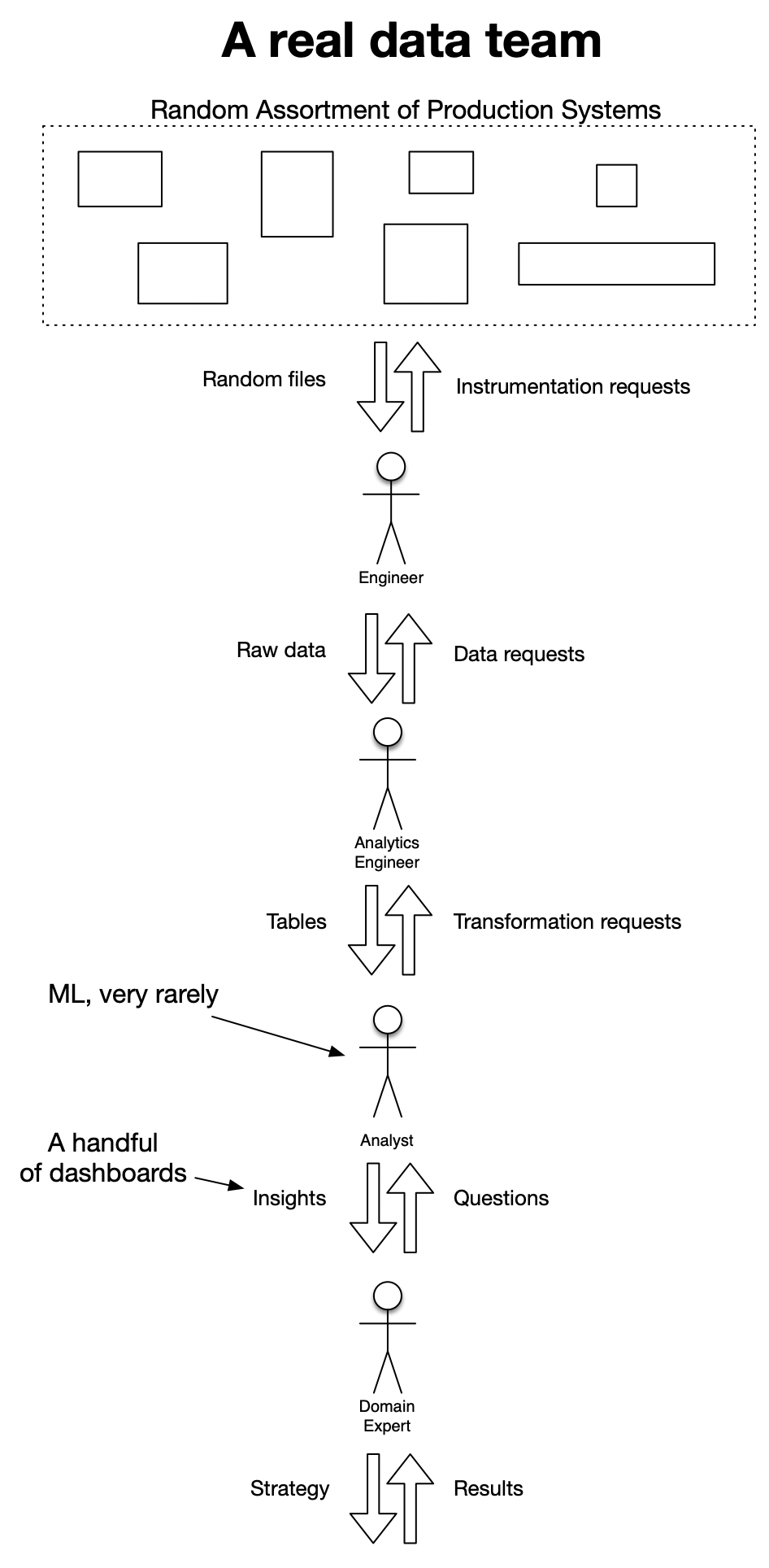
Learning 2: running a data warehouse is not your job
Another pitfall tech companies run into, when they have a data problem, is thinking because they are a tech company, and running a data warehouse is technical, that's a thing they should be able to do. Again, like hiring a data scientist for data, it seems logical! But data warehouses are their own complicated beasts. They do not follow the same operational constraints and they have different scaling properties to whatever databases it is you're running in production.
Unless what your company does is run data warehouses, you should be buying your data warehouse from somebody else. Any money you save from not paying for a data warehouse service will be eaten by the engineering time you spend operationalizing a data warehouse, and it will never be as fast and scalable as one run by experts. I don't have strong opinions about which data warehouse to use -- I've used Redshift, AWS Athena, Databricks and Snowflake -- but I do believe strongly that you should get someone else to run it unless you are a very big company.
Learning 3: there are frameworks now
For the first 10 years of messing with data, my "data pipeline" code was always a roll-your-own deal. Data would be accumulating in logs somewhere, it might be in CSV format, or Apache log format, or maybe newline-delimited JSON. It might be one file per day, or per hour, or per minute. The files might be any kind of size from a few megabytes to thousands of gigs. I would write some code in whatever language happened to be lying around to parse and extract this, maybe get some cron jobs going, load it into a database that was lying around handy, maybe slap some graphs on top. It worked! But it was its own special snowflake, and it seldom scaled.
We had the same problem in web development -- you could build a website an infinite number of ways, and that was the problem, because no two people would pick the same way, so they'd fight about it, or misunderstand how it worked, and everyone was constantly rewriting from scratch because they couldn't figure out the last thing.
This changed -- at least for me -- around 2006, when I heard about Ruby on Rails. Ruby is not my favorite language, but Rails was a revolution. Rails provided an opinion about the Right Way To Do It. It wasn't necessarily always really the best way to do it, but the surprising lesson of Rails is everybody doing it the same way is, in aggregate, more valuable than everybody trying to pick the very best way.
The revolution Rails and the blizzard of frameworks that followed it enacted was that you could hire somebody into your company who already knew how your website worked. That was a gigantic breakthrough! Instead of spending half your time fighting bugs in your architecture, the framework maintainers mostly took care of the architecture and you could fight bugs in your business logic instead. The result was a massive reduction in work for any individual developer and a huge acceleration in the pace of web development as a whole.
Rails was invented in 2004, but as I mentioned I came across it in 2006 and felt somewhat like I was late to the party. There was a Right Way To Do It now, and I'd spent 2 years doing it the "wrong" way! Damn! Better catch up! I never actually ended up building a site in Rails (I simply did not enjoy Ruby), but I picked up copycat frameworks in other languages and was off to the races.
Coming across the two frameworks for data engineering in 2020, Airflow and dbt, felt very much like finding Rails in 2006, except I'm even later to the party. Airflow and dbt were both first released in 2016.
Airflow
I'm not going to talk too much about Airflow simply because I don't know that much about it. In the diagram above, I live in steps 3-5, and not even 3 that often as our team has grown. Airflow lives at steps 1 and 2. It allows you to create chains of data extraction jobs that depend on each other, to pull piles of random files continuously from all the places they can go, transform them into tables, and put them where they need to be. It handles all sorts of niceties like timing, error detection, retrying, and more. Very importantly, the configuration of Airflow lives mostly in Git, meaning you can have version control, code reviews, and all the things you'd expect to have of any other critical part of your infrastructure, and which have been notably absent from many of the home-grown solutions I've seen.
It's all a huge leap forward from cron jobs and bash scripts, and the members of my team who take care of Airflow for us are heroes. The tables created in Airflow are the foundation on which dbt rests.
dbt
dbt, which stands for "data build tool", is the framework I know more about. At its most basic, dbt allows you to write SQL queries which automatically become queryable views. Those views can be referenced in other views, and those further referenced, allowing you to build an elegant tree of data provenance from its original raw form to collated, aggregated, filtered collections that answer your questions. If you make a change to an upstream view, the downstream views are automatically refreshed.
On top of that, you can selectively declare a view to be "materialized", i.e. made into a table rather than a view. You might want to do this for performance reasons, since views that depend on views can get quite slow. Every time new data arrives in the upstream views, the downstream tables will be automatically rebuilt by dbt, so you never end up with stale data. If that rebuild process begins to get slow, you can further declare a table to be "incremental", meaning only new data will inserted or updated, rather than replacing the entire table each build.
Finally, you can declare basic tests for all your tables -- is this column supposed to be unique? Are nulls a problem here? You don't need to write any test code, you can just declare these features as a property of your view or table and every time your tree of tables is rebuilt, those properties will be checked.
And like Airflow, all of this configuration and declaration can live in Git, so your team can have version control, code reviews, staging builds and everything else a modern engineering team expects when collaborating.
None of this is ground breaking. Anybody who's built a data pipeline has come up with some way to declare that tables depend on other tables, to rebuild them, and to test them. What dbt does, like Airflow, is a provide a known way to do that. You can hire people who know dbt and Airflow and they can be productive on their first day, without you having to guide them through your special snowflake of a data architecture. It's simultaneously simple and yet as revolutionary for the data team as Rails was for the web team.
Learning 4: a data team is nothing without domain experts
My final learning is cheating a little bit, because I knew it already, but I have seen a great number of startups hiring for data fail to understand it: your data team is good at data. They have a great number of specialized skills for wrangling it, querying it, making sense of it, and visualizing it. They are experts at data. What they are not experts at it your business.
The data scientist hired in the original diagram will flail at steps 1-3 but even when they get through them they will flail again at step 5. You know what your goals are; you know who your customers are; you know what they are trying to achieve; you know what your product is capable of, and what it does not do. Your data experts do not know these things, at least at first. A data team hired in isolation without working closely with domain experts from within the business is going to do a huge amount of work and produce nonsensical results based on inaccurate assumptions. A data team without close partnership to ask the right questions and feed back on results is useless. This is why I went to work as a data analyst at a web company; I know the domain, so I can frequently ask the right questions.
Still learning
While all of this has been great fun to learn and apply, and I feel a hundred times more productive as a data person than I did 18 months ago, there are still some big, unsolved problems that I don't have answers for yet:
1. Should the business self-serve data?
Data tool vendors love to sell that their fool-proof SQL interface means that stakeholders can "write their own queries" or even "build their own dashboards with no code". I'm split on the question. Lots of people know SQL and can make useful progress on their own, and data teams shouldn't gatekeep them. On the other hand, querying the wrong table, or misunderstanding a result, can produce inaccurate conclusions that a dedicated data person wouldn't make. So is self-serve worth it? I don't know. My current compromise is that I recommend people try to self-serve and then run what they've built past the data team to check their work, but it's not a perfect solution.
2. What about dashboards?
Everybody who does an analysis once ends up wanting it run all the time. The solution is dashboards: you create a query that lives at a URL, and it can be revisited and refreshed at will. In practice, dashboards get stale very quickly as the business changes around them, and are seldom documented well enough for it to be obvious when any particular dashboard should no longer be considered reliable. Also, dashboards accumulate over time, making it difficult for newcomers to find the most important data. Dashboards are great but maintaining dashboards seems to be a full-time job, and the information about which dashboards are important and reliable lives in the heads of the data team, which is not a good solution.
3. How should discovery work?
A business of any size breeds data at a bewildering rate. New products, new features, new pricing, new analyses can quickly produce hundreds of tables. A new data team member, or even an existing one, can find it impossible to know which tables are suitable for which purpose, and which data lives where. dbt addresses this with documentation of tables in the code, down to the column label, and auto-generating searchable documentation. But being able to find every column that contains the word "revenue" and knowing which table is the right one to answer the specific question about revenue you have today are very different things. Again, the answers to this currently lie in the collective knowledge of the data team, and that's not a scalable answer.
We are of course not sitting on our hands perplexed by these problems, and are trying many solutions, including process changes and third-party tools from the exponentially-growing collection of data tool vendors who email us every day. But I don't like any of the answers I've seen yet.
More to come
The last 18 months have been tremendous at up-leveling my understanding of how a data team should be built and run and I'd like to call out Emilie, the manager of Netlify's data team, who joined six months after I did and has been responsible for introducing me to a great deal of this stuff, as well as hiring a great team to get it all done.
As I was with web frameworks, I feel like I have arrived late to the data management party, but it's a party nevertheless. I look forward to another year of learning.
